
COSMIC进阶(一)
COSMIC进阶
前言:虽然标题有(一),但是并不一定会有(二)!!!因为写东西还是比较费时间的,可能碰见什么感兴趣的,觉得别人没碰过的,又觉得对其他有帮助的才会花时间写吧。
首先我们以FAT1基因为例,打开cosmic网站的FAT1页面FAT1_COSMIC,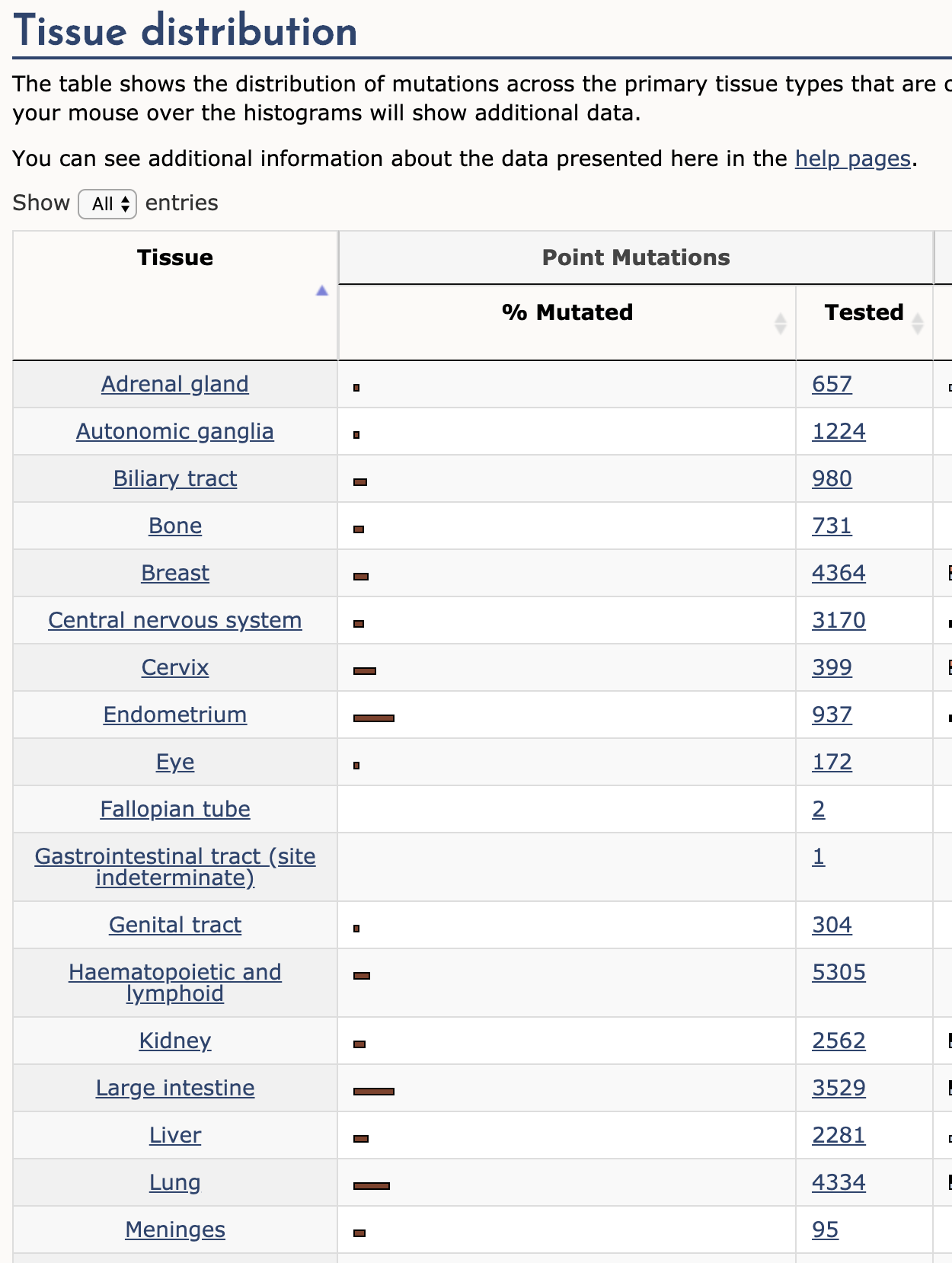 然后在页面中的Tissue Distribution为例,可以看到列出了FAT1基因在各个不同癌症中的突变频次和频率,假设我们对Cervix感兴趣,那么我们在Cervix里链接中打开Cervix的链接FAT1_cervix,
然后在页面中的Tissue Distribution为例,可以看到列出了FAT1基因在各个不同癌症中的突变频次和频率,假设我们对Cervix感兴趣,那么我们在Cervix里链接中打开Cervix的链接FAT1_cervix,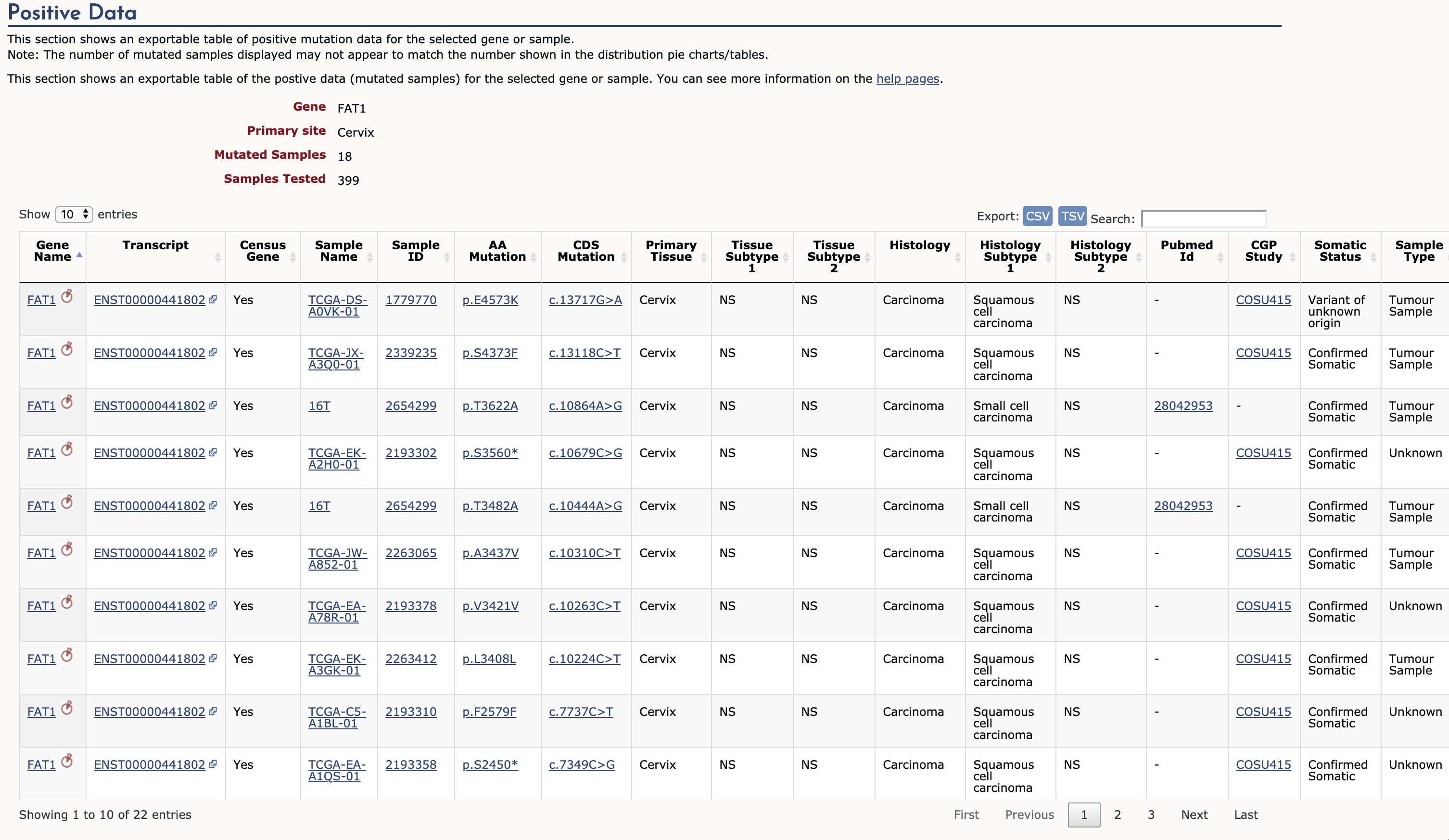
web api结果
我们可以看到,FAT1基因在cervix样本中有18个sample是发生了FAT1突变,在最下方可以看到总共有22个entries,也就是说18个样本中在FAT1基因中总共发生了22次突变。
以上操作是我们在cosmic的web api中人工查询到的数据,那么问题来了!这个18和22个突变数据是怎么来的呢??我们在图2右上角可以看到搜索结果可以导出csv和tsv格式的数据(需要注册),但是我们在生信流程中肯定是自动完成这个步骤的,不可能人工一个一个去找啊。但是也不能一个一个在web上去导出啊。所以我们就最要弄清这些搜索结果到底在底层是怎么来的呢?
web结果有现成的数据库吗?
我花了好几天的时间专门去研究了一下cosmic数据库(包括VEP中对cosmic的描述),对cosmic的内容和格式也仔细研究了一下,那么对于上面提出来的这个问题,我的答案就是:很遗憾,除了人工导出数据,官方没有现成的数据供你直接下载使用。
但是!所以有但是一定会有转机的对不对。如果真的只能靠人工的话,那么这个数据库也不会有什么影响力了吧。既然没有现成的,那就自己去算一遍咯!
了解COSMIC
首先,我们搜索出来的这些数据(FAT1基因在cervix中的样本)是有具体范围的,所以其实这个搜索是根据某些规则去匹配的,所以换个思维去想,你想搜索什么规则是不确定的,数据库不可能针对某个规则专门去做一个数据库,所以这些数据的存在必定是在一个很全的汇总的文件里面,根据这个文件再去提炼。挑选出来的。
事实上,当我们在cosmic 的download页面可以发现,cosmic的数据库总共也就那么几个,包含了fusion,Classification,mutation,Census Genes等等,所以我们需要在这些数据库中去寻找上面的结果是怎么在数据库中匹配的。
重现web统计结果
cosmic的数据库这里就不多说了,要了解精通它,只能自己花时间去看,这个过程只能自己去花时间消化。回到主题,要重现web结果其实非常简单。
- 我们把目标定义在CosmicMutantExport.tsv这个数据库文件(为什么是这个文件呢?有讲究的,请自行查阅理解),可以去看看这个文件有什么信息,官方网站有数据库的详细介绍,大概是注释了35列信息。
- 我们直接对数据库文件进行查找
grep FAT1 CosmicMutantExport.tsv >fat1.tsv(当然还可以用awk,数据库非常大,grep和awk谁速度快应该也是一个问题,不过也花不了多少时间,就用不着考虑速度问题了) - 上一步就可以得到所有FAT1的信息,fat1.tsv其实就是CosmicMutantExport.tsv的一个fat1基因的子集,进去看看可以知道总共有3024条记录,当然这不是我们想要的,我们需要对这个子集再次进行二次筛选
- 二次筛选也很简单
grep cervix fat1.tsv > fat1_cervix.tsv,得到最后的一个fat1_cervix.tsv的结果文件,我们看看这个结果文件,22行。再根据上图可以知道web api有22个entries,我们再把web结果和flat1_cervix.tsv结果进行对比,一模一样! entries数目和内容已经确定完全正确了,web api结果显示的FAT1中cervix的突变样本样本是18个,比entries小,原因也很简单,某些cervix样本在FAT1基因上发生了大于1个的突变。如果想确认下,可以根据数据库中Sample name列或者ID_sample列去统计,去重后也确实是18。
所以,从原始的数据库中,也仅仅是用了2个最简单的命令就完成了web api结果的提取,当然这是建立在你对cosmic数据库的基本了解上。如果对cosmic数据库非常了解,将可以挖掘非常多的信息。
另外的问题
那么最后,再带来一个问题,在图一中可以看到,cervix的tested值是399,也就是测试了399个cervix样本,% mutated的柱状图是表示比例和数目,鼠标悬浮在上面的时候会显示
Total Samples tested:399
Total Mutated samples:18
Total Percentage of samples mutated:4.51
也就是说cervix突变样本比例是18/399=4.51%,这个信息应该也是注释中一个很有参考价值的信息,但是很遗憾,这个数据同样是在数据库中没有直接列出来的,需要再次进行二次统计计算。所以问题就是,这个399和4.51%的比例是怎么来的?
另外还有些可能会看到的注释,比如
NS(201) biliary_tract(28) bone(27) breast(401) central_nervous_system(100) endometrium(24)
统计的是在不同样本出现突变的频次,这个数据库我在GATK里能够找到,根据它引用的信息,知道它的也是根据COSMIC数据库进行二次统计得到的,但是可能也是因为授权的原因,版本一直很落后,那么如何根据官方COSMIC数据库,自己进行处理更新这个数据库呢??
这些问题就留给感兴趣的朋友去解决吧,只能说,如果真的了解COSIC的话,这都不是很难的工作。
总结
最后对cosmis数据库做个总结吧
- cosmic是癌症领域中非常活跃也非常权威的数据库,它包含了非常多的可以挖掘的信息
- cosmic数据库因为需要注册,而且因为授权的原因,在某些注释数据库中不能自由的使用(比如我所熟悉的vep是无法获取cosmic大部分信息的)
- web api查询出来的很多东西都是无法在数据库中找到现成的注解的,必须要通过二次计算才能得到和web api的结果,所以要想对cosmic数据库进行工业级的应用,二次开发在所难免
- 人为预处理二次开发后的cosmic数据库可以搭配注释软件的plugin功能进行自定义的数据库匹配,实现注释的个性化功能,个性化解读。当然这个功能的实现需要对cosmic数据非常了解,也需要对注释软件非常了解,比较有难度